Daehan Lim
Machine Learning Projects
📂 Projects Overview
- Privacy-Preserving Federated Random Forest - Privacy-preserving distributed learning system (2023) ⎆
- RoBERTa News Classification - Enhanced topic classification with synthetic data (2024) ⎆
- Medical Data Classifier - Patient mortality prediction system (2023) ⎆
- Information Retrieval System - Document indexing and search system (2024) ⎆
Privacy-Preserving Federated Random Forest
Privacy-preserving distributed learning system for collaborative model training (2023)
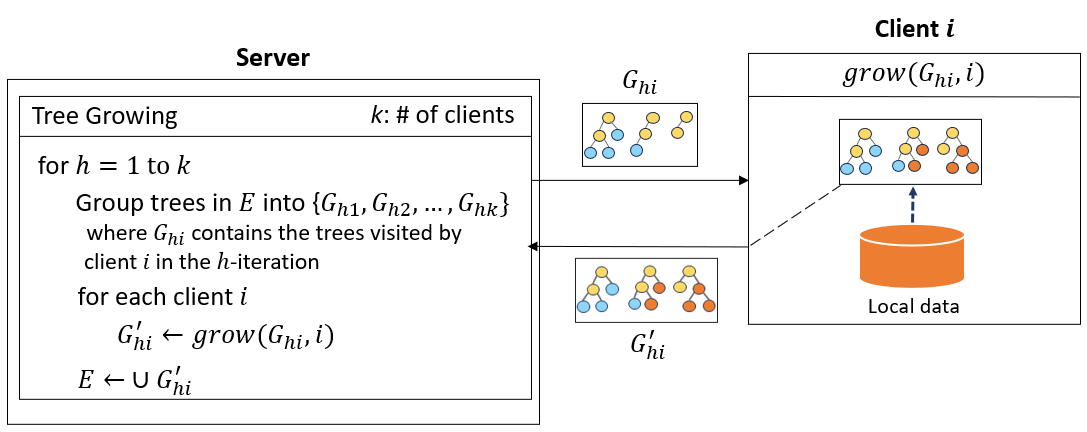
Overview:
- Designed and implemented a federated learning system for random forests enabling privacy-preserving distributed model training across multiple clients
- Implemented parallel processing pipeline using Python’s ProcessPoolExecutor for efficient multi-client simulation and simultaneous model training, reducing training time by 60%
- Introduced incremental learning mechanism that enables efficient integration of new clients without full model retraining, improving system scalability
- Demonstrated system effectiveness through extensive testing across 7 benchmark datasets with sizes ranging up to 88,000 samples and 54 features, achieving a 10% performance improvement compared to the baseline approach
- Published research in Expert Systems with Applications (SCIE Journal) and resulted in patent filing (Appl. No. 10-2024-0001659)
- Tech Stack: Python, NumPy, Pandas, scikit-learn, Matplotlib, multiprocessing, Graphviz
RoBERTa News Classification
Enhanced topic classification model with synthetic data augmentation (2024)
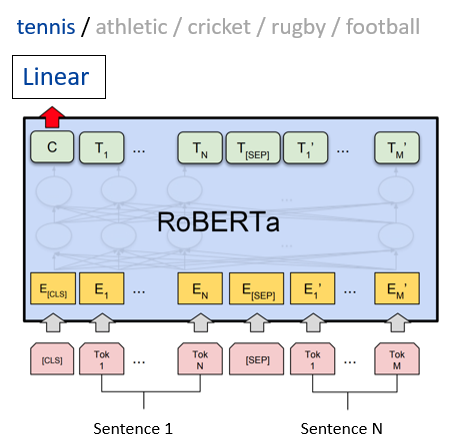
Overview:
- Developed machine learning model for classifying sports news articles into 5 distinct categories using RoBERTa and BBC Sport dataset
- Augmented limited training data using GPT-4 generated articles and prompt engineering techniques, improving classification accuracy to 99.5%
- Employed zero-shot learning strategy to enhance diversity and versatility of the LLM generated articles
- Executed comprehensive experiments evaluating model performance under various data configurations and training conditions
- Developed and deployed web application using Streamlit, enabling real-time article classification with detailed performance visualizations
- Tech Stack: Python, PyTorch, Hugging Face Transformers, GPT-4, Streamlit
Medical Data Classifier
Novel classification system for patient mortality prediction using electronic health records (2023)

Overview:
- Developed custom associative classifier tailored for unbalanced healthcare datasets
- Generated interpretable rules for medical decision-making, enabling healthcare experts to validate model predictions
- Implemented efficient rule-pruning strategy, reducing rule set by 80% for enhanced model interpretability
- Achieved superior performance metrics compared to traditional classifiers on real-world hospital data
- Tech Stack: Python, NumPy, Pandas, scikit-learn, Jupyter
Information Retrieval System
Efficient implementation of Boolean and ranked document retrieval (2024)
Overview:
- Reduced document processing time by 65% compared to sequential search by implementing SPIMI-based inverted indexing
- Enhanced search precision through Boolean operator (AND, OR, NOT) based filtering
- Implemented ranked retrieval using TF-IDF weighting and cosine similarity, improving search result relevance
- Achieved 0.3 second average search response time for 466 English documents
- Implemented system with optimized memory usage of 2.5MB
- Tech Stack: Python, NLTK, SpaCy, NumPy, contractions