Daehan Lim
머신러닝 프로젝트
📂 프로젝트 목차
- 연합학습 기반 랜덤 포레스트 - 개인정보를 보호하는 분산 학습 시스템 (2023) ⎆
- RoBERTa 뉴스 분류기 - 합성 데이터를 활용해 성능을 개선한 주제 분류 모델 (2024) ⎆
- 의료 데이터 분류 시스템 - 환자 사망률 예측 시스템 (2023) ⎆
- 정보 검색 시스템 - 문서 색인화 및 검색 시스템 (2024) ⎆
연합학습 기반 랜덤 포레스트
분산 환경에서 데이터 보안을 보장하는 협업 학습 시스템 (2023)
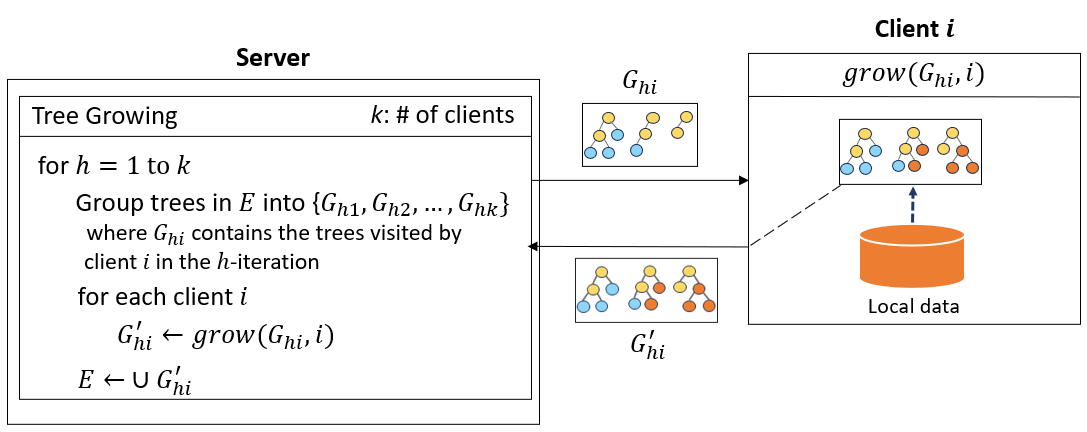
소속: 충남대학교 데이터마이닝 연구실 역할: 전체 시스템 설계 및 구현, 논문 작성, 특허 출원
수행 내용:
- 다중 클라이언트 간 프라이버시를 보장하는 연합학습 기반 랜덤 포레스트 시스템 설계 및 구현
- ProcessPoolExecutor를 활용한 트리 학습 병렬화로 모델 훈련 시간 60% 단축
- 전체 모델 재학습 없이 새 클라이언트 추가 및 업데이트 가능한 점진적 학습 메커니즘 도입으로 시스템 확장성 향상
- 7개의 데이터셋(최대 88,000개의 샘플, 54개의 특성)에서 기존 접근법 대비 10% 성능 향상 달성
- Expert Systems with Applications (SCIE 저널) 논문 게재 및 특허 출원 (출원 번호 10-2024-0001659)
- 사용 기술: Python, NumPy, scikit-learn, Matplotlib, multiprocessing, Graphviz
RoBERTa 뉴스 분류기
합성 데이터 증강을 활용한 고도화된 주제 분류 모델 (2024)
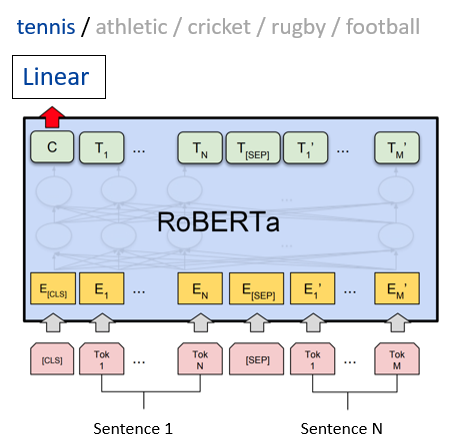
소속: 충남대학교 데이터마이닝 연구실 역할: 분류 모델 구현, 합성 데이터 생성, 웹 애플리케이션 개발
수행 내용:
- RoBERTa와 BBC Sport 데이터셋을 활용해 스포츠 뉴스를 5개의 카테고리로 분류하는 머신러닝 모델 구현
- GPT-4로 생성된 합성 데이터 및 프롬프트 엔지니어링 기법 도입으로 분류 정확도 99.5%로 향상
- Zero-shot 학습 전략 도입으로 합성 데이터의 다양성 및 범용성 확보
- 다양한 데이터 구성과 훈련 조건에서의 모델 성능 평가를 위한 포괄적 실험 수행
- 실시간 기사 분류와 성능 시각화를 제공하는 웹 애플리케이션 개발 및 배포로 사용자 접근성 향상
- 사용 기술: Python, PyTorch, Hugging Face Transformers, GPT-4, Streamlit
의료 데이터 분류 시스템
전자의무기록 기반 환자 사망률 예측을 위한 연관 규칙 분류 시스템 (2023)

소속: 충남대학교 데이터마이닝 연구실 역할: 전체 시스템 설계 및 구현, 논문 작성
수행 내용:
- 의료 데이터의 클래스 불균형 문제를 해결하는 맞춤형 연관 규칙 분류기 설계 및 개발
- 의료진의 결과 검증을 위한 해석 가능한 규칙 생성 시스템 구축으로 예측 투명성 확보
- 효율적인 규칙 가지치기 전략 도입으로 분류 규칙 수를 80% 감소시켜 모델 해석성 개선
- 실제 병원 데이터 기반 실험에서 기존 분류 모델 대비 우수한 성능 달성
- 사용 기술: Python, NumPy, Pandas, scikit-learn, Jupyter Notebook
정보 검색 시스템
효율적인 불리언 및 랭킹 기반 문서 검색 시스템 구현 (2024)
소속: 충남대학교 역할: 전체 시스템 설계 및 구현, 논문 작성
수행 내용:
- SPIMI 기반 역색인 구축으로 순차적 검색 대비 문서 처리 시간 65% 단축
- 불리언 연산자(AND, OR, NOT) 기반 정밀 검색으로 검색 결과 필터링 정확도 향상
- TF-IDF 가중치와 코사인 유사도를 활용한 문서 랭킹으로 검색 결과 적합도 개선
- 466개의 영문 문서 처리 시 평균 검색 응답 시간 0.3초 달성
- 메모리 사용량을 2.5MB로 최적화된 시스템 구현으로 리소스 사용 효율성 확보
- 사용 기술: Python, NLTK, SpaCy, NumPy, contractions